





집계함수는 결과 레코드들에 대한 레코드의 개수, 값들의 합, 평균, 최대값, 최소값 등의 산술적인 연산을 한 결과값을 출력한다.
다음은 MySQL에서의 집계함수 목록이다.
| 집계함수 | 의미 |
|---|---|
| count(필드명) | null 값이 아닌 레코드의 수 |
| sum(필드명) | 필드명의 값들의 합계 |
| avg(필드명) | 필드명의 값들의 평균 |
| max(필드명) | 필드명의 값들 중 가장 큰 값 |
| main(필드명) | 필드명의 값들 중 가장 작 값 |
| count(*) *은 모든것을 의미 |
레코드의 개수 |
지금부터 배울 집계함수를 배우기 위해서는 새로운 테이블을 만들어야 합니다.
그럼 아래의 테이블을 만들어보죠
| num | name | gender | job | area | rank | |
|---|---|---|---|---|---|---|
| 20200001 | elsa | w | princess | arendal | elsa@everdevel.com | 5 |
| 20200002 | mickey | m | magician | usa | mickey@everdevel.com | 7 |
| 20200003 | minnie | w | disney character | usa | minnie@everdevel.com | 2 |
| 20200004 | rapunzel | w | princess | usa | rapunzel@everdevel.com | 3 |
| 20200005 | snow white | w | princess | usa | snow@everdevel.com | 4 |
| 20200006 | mike wazowski | m | Scarer | usa | wazo@everdevel.com | 5 |
| 20200007 | hiro | m | scientist | usa | bighero@everdevel.com | 6 |
| 20200008 | Yi Sun sin | m | general officer | korea | korea@everdevel.com | 1 |
| 20200009 | honda souichiro | m | engineer | japan | honda@everdevel.com | 8 |
| 20200010 | cinderella | w | princess | usa | bibidibabidiboo@everdevel.com | 9 |
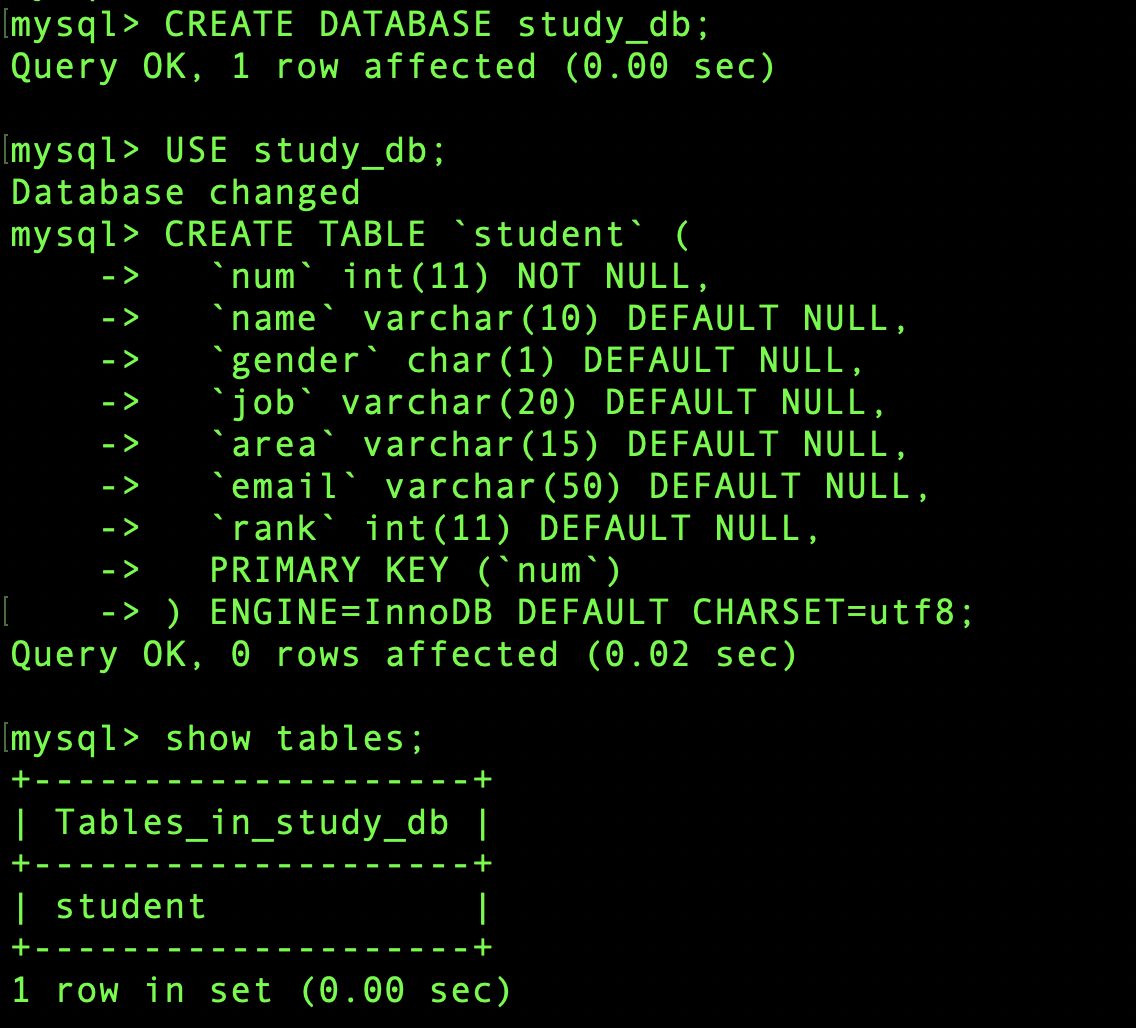
데이터베이스는 study_db , 테이블명은 student로 하겠습니다.
그럼 먼저 데이터베이스를 생성해 주세요.
CREATE DATABASE study_db;
그럼 테이블을 만들겠습니다. study_db를 선택해 주세요.
USE study_db;
다음은 student로 테이블 생성 명령문입니다.
CREATE TABLE `student` (
`num` int(11) NOT NULL,
`name` varchar(10) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`job` varchar(20) DEFAULT NULL,
`area` varchar(15) DEFAULT NULL,
`email` varchar(50) DEFAULT NULL,
`rank` int(11) DEFAULT NULL,
PRIMARY KEY (`num`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
테이블을 만들었으니 이제 데이터를 입력하겠습니다.
INSERT INTO student VALUES(20120001, 'elsa', 'w', 'princess', 'arendal', 'elsa@everdevel.com', 5);
INSERT INTO student VALUES(20200002, 'mickey', 'm', 'magician', 'usa', 'mickey@everdevel.com', 7);
INSERT INTO student VALUES(20200003, 'minnie', 'w', 'disney character', 'usa', 'minnie@everdevel.com', 2);
INSERT INTO student VALUES(20200004, 'rapunzel', 'w', 'princess', 'usa', 'rapunzel@everdevel.com', 3);
INSERT INTO student VALUES(20120005, 'snow white', 'w', 'princess', 'usa', 'snow@everdevel.com', 4);
INSERT INTO student VALUES(20200006, 'mike wazowski', 'w', 'Scarer', 'usa', 'wazo@everdevel.com', 5);
INSERT INTO student VALUES(20200007, 'hiro', 'm', 'scientist', 'usa', 'bighero@everdevel.com', 6);
INSERT INTO student VALUES(20200008, 'Yi Sun sin', 'm', 'general officer', 'korea', 'korea@everdevel.com', 1);
INSERT INTO student VALUES(20200009, 'honda souichiro', 'm', 'engineer', 'japan', 'honda@everdevel.com', 8);
INSERT INTO student VALUES(20200010, 'cinderella', 'w', 'princess', 'usa', 'bibidibabidiboo@everdevel.com', 9);
위의 명령문을 입력합시다.
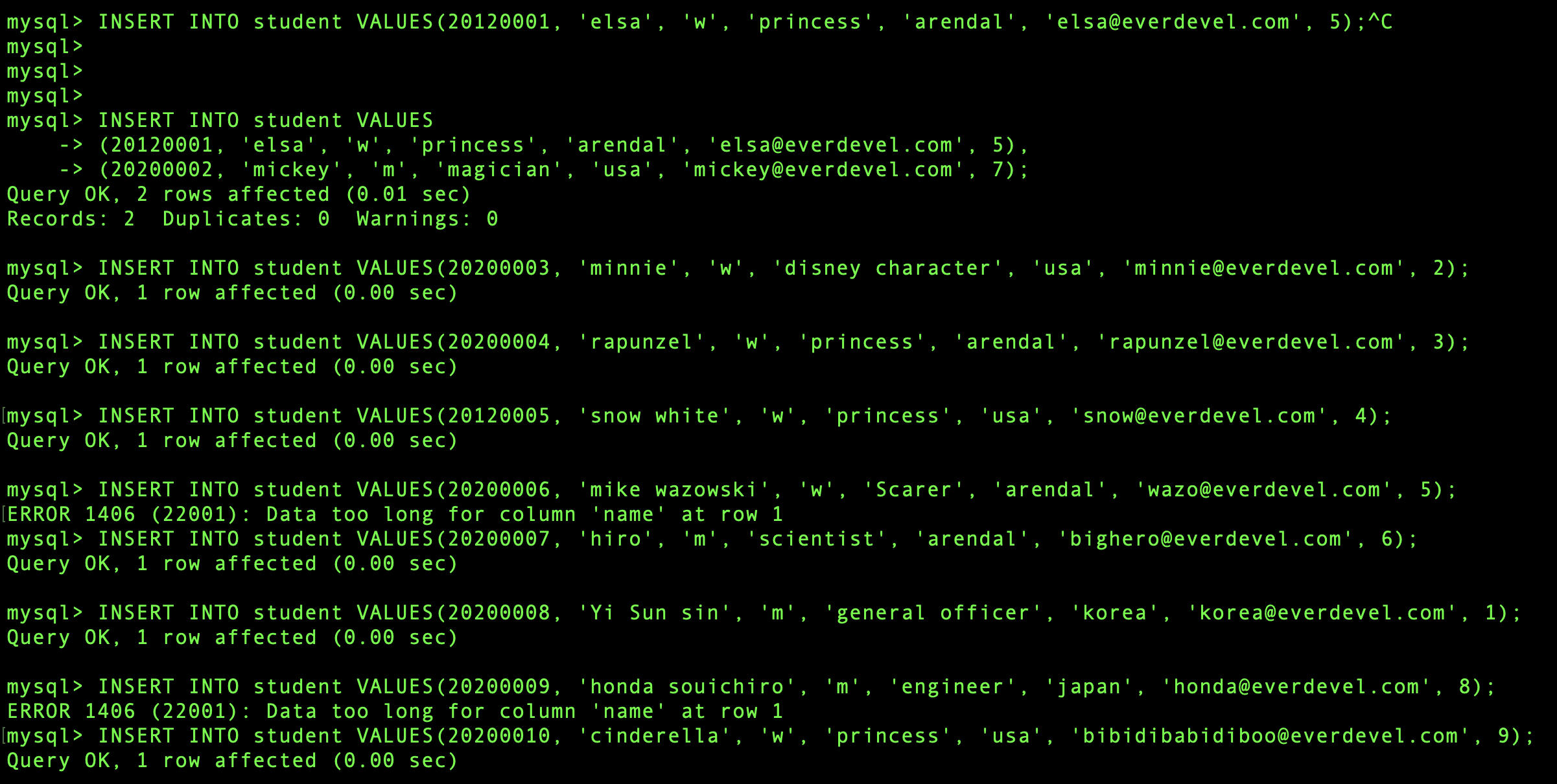
mike wazoski와 honda souichiro는 문자열의 길이가 name필드에 설정된 값보다 길어서 오류가 발생했습니다.


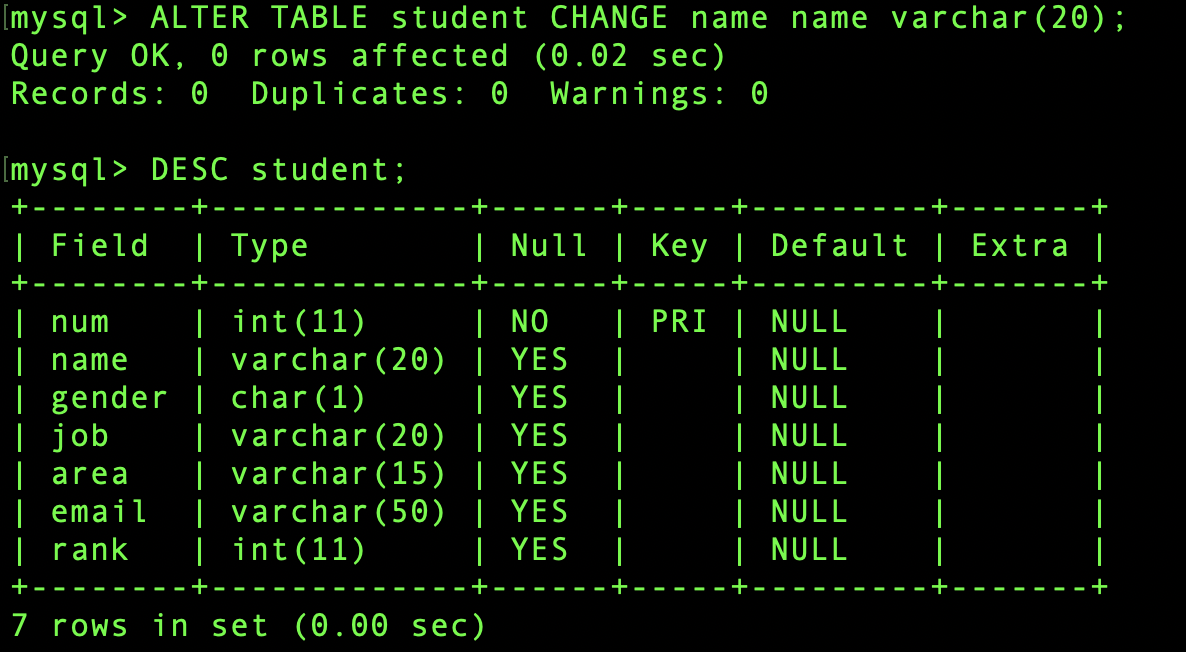
name 필드의 값을 더 늘립니다. varchar(10)을 varchar(20)으로 변경합니다.
ALTER TABLE student CHANGE name name varchar(20);
DESC student;
SELECT * FROM student;
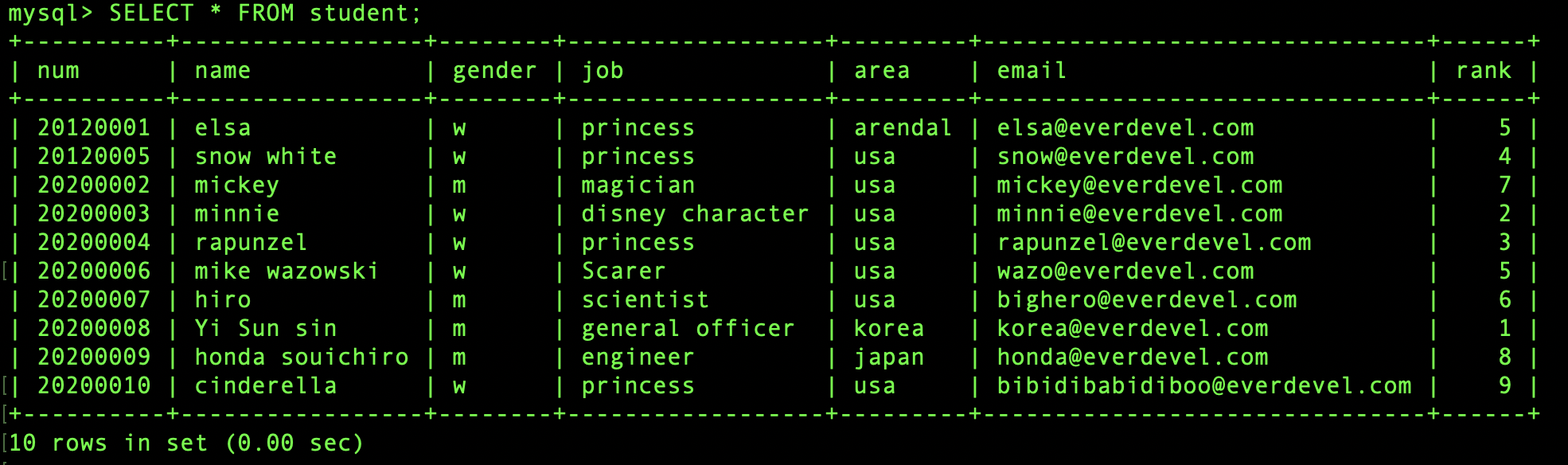
그럼 이제 집계함수에 대해서 공부해보도록 하죠!!
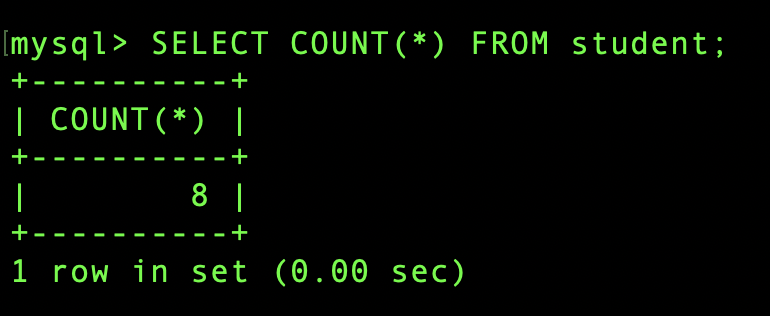
전체 학생의 수를 검색 해 봅시다.
아래의 명령어를 입력
SELECT COUNT(*) FROM student;
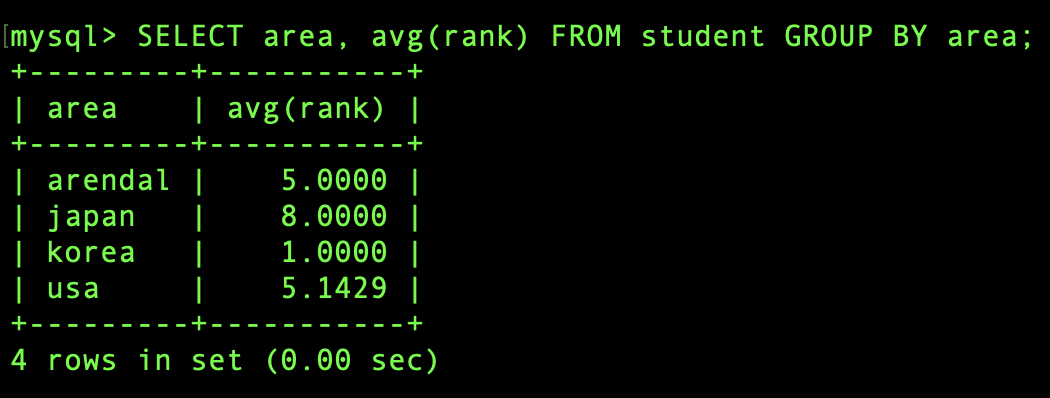
그럼 이번엔 각 지역별 랭킹 순위를 구해봅시다.
지역별(area)로 그룹화 합니다. GROUP BY 문을 사용합니다.
SELECT area, avg(rank) FROM student GROUP BY area;
위의 명령문은 보일 필드는 area와 rank입니다.
평균값을 보기 위해 avg함수를 사용했고 rank값들의 area별 평균값이 나타납니다.
위에 보듯이 각 전공별로 재산이 합해져서 나왔습니다.
이번에는 특정 문자열을 가진 레코드를 검색해봅시다.
특정 문자열을 가진 레코드를 검색하기 위해 사용되는 연산자는 like이며, 문자열 상수에 일치하기 위한 문자 '_'(언더스코어)와 %(퍼센트)가 제공된다.
_ 임의의 한문자 (한글의 경우 2바이트이므로 2개 사용)
% 퍼센트 (임의의 여러 문자(숫자0을 포함)
그럼 이름이 m으로 시작하는 레코드를 찾아봅시다.
이거 레코드검색에서 했던거죠^^
SELECT * FROM student WHERE name LIKE 'm%';

like 대신에 not like를 사용해봅시다.
SELECT * FROM student WHERE name NOT LIKE 'm%';

m으로 시작하는 이름을 제외하고서 다 검색되죠^^
이렇게도 가능합니다. 이름끝에 o가 들어있지 않는 사람 찾기
SELECT * FROM student WHERE name NOT LIKE '%o';

이번에는 이름이 4글자 이면서 이름끝에 o가 들어가는 사람을 찾아봅시다._(언더바)를 3회 사용합니다.
SELECT * FROM student WHERE name LIKE '___o';

그럼 이번에 usa에사는 이름이 m으로 시작하는 가진 사람을 찾아봅시다.
SELECT * FROM student WHERE area = 'usa' AND name LIKE 'm%';

다음강좌 에서는 레코드 변경 및 삭제에 대해서 알아봅시다.!!
현재까지의 db 백업 (아래는 현재까지의 작업을 백업한거라서 중도에 들어오신분들을 위한거에요.)
david_db smart study_db봐주셔서 감사합니다. 문의 또는 잘못된 설명은 아래의 댓글에 부탁드립니다.
당신의 작은 누름이 저에게는 큰 희망이 됩니다.

댓글 0개
정렬기준


